第6章 目标检测
6.1 目标检测要判断什么
第4章把回波里的时间延迟变成了距离,第5章把回波里的相位变化变成了速度。处理到这里,很容易产生一个误会:距离像或者距离-速度图上只要有个峰,不就说明那里有目标吗?
真实雷达数据没有这么干净。峰值并不只来自目标:噪声会抬出小尖峰,杂波会形成大片背景起伏,强目标旁边的旁瓣也会制造看起来像目标的结构。如果看到一个凸起就认定有目标,误报会多到无法使用。
所以第6章解决的是一个很现实的判断问题:眼前这个峰,到底该不该信?
前面的处理已经给出了距离像或距离-速度图;检测要在这张图上再做一次筛选:通过门限的位置记为 1,没通过的位置记为 0。这样得到的 0/1 图称为检测掩码或检测图。检测掩码中为 1 的格子,才会进入点迹生成和目标列表整理流程。
从亮点到判决
检测判决可以从一条距离像看得最清楚。假设匹配滤波之后,某一段距离像中 8 个距离单元的幅度为
第 5 个单元的幅度是 4.7,比周围背景高出很多。这样的峰通常很像目标,因为周围大多在 1 左右,而它突然抬到了 4.7。
把数据稍微换一下:
第 5 个单元现在只有 1.6。它仍然比周围高,但这个差距已经不那么可靠。它可能是一个弱目标,也可能只是噪声恰好高了一次。检测的难点在于这类“不够明显,但又不能随便忽略”的格子。
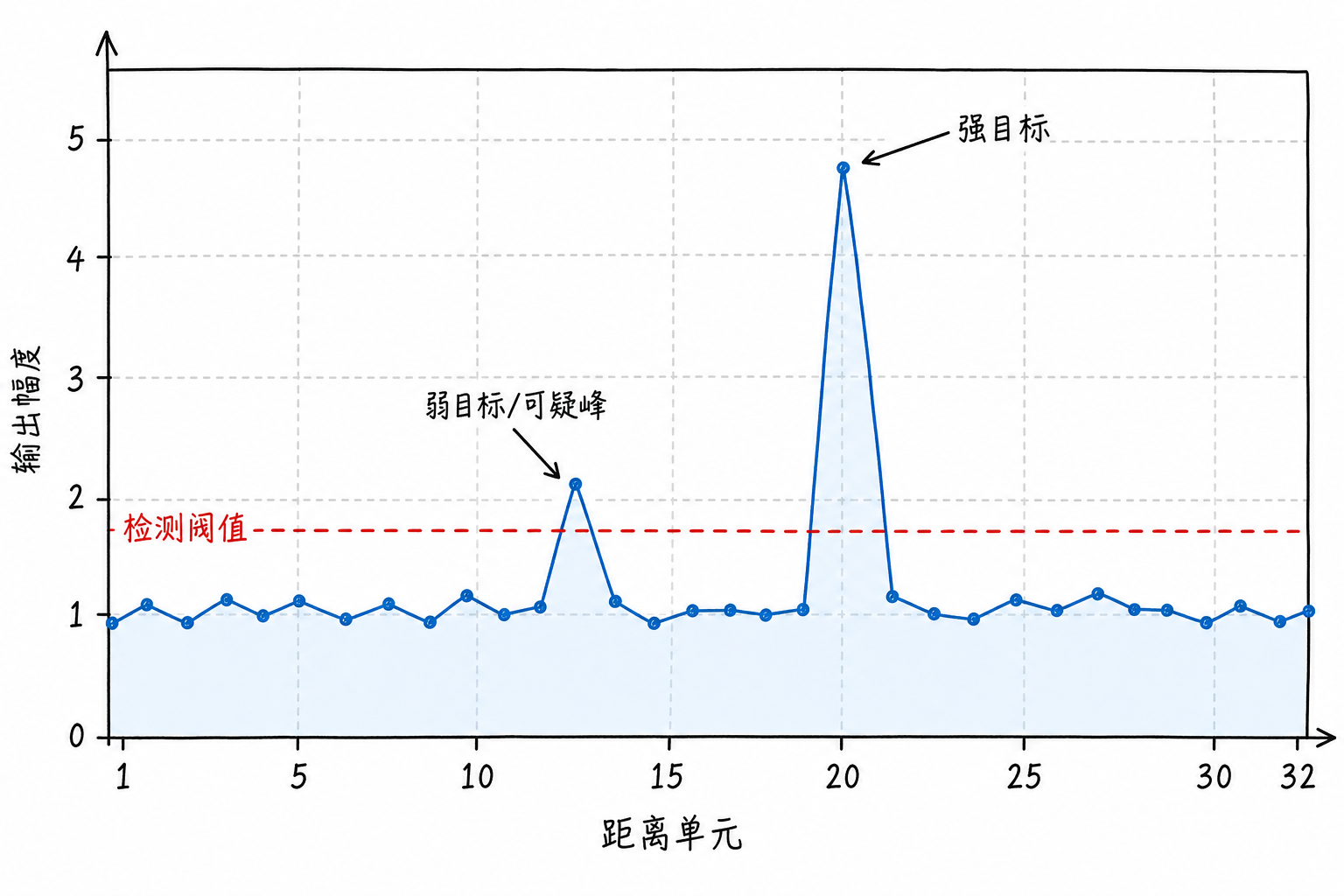
图6.1 里,强目标很容易判断;弱目标和噪声起伏之间的边界更模糊。检测问题处理的是另一层任务:在一堆起伏里分辨,哪个凸起值得相信,哪个只是背景偶然冒高了一下。
在距离-速度图上也是同一件事。每个格子对应一个距离和一个速度,检测器并不重新发明距离和速度,只是在问:这个格子的能量相对背景是否足够可信?如果可信,它就在检测掩码中被标成 1;如果不可信,它仍然只是图上的一个起伏。
两种检测假设
实际接收输出不可能完全干净。即使没有目标,接收机热噪声、地杂波、海杂波、旁瓣和频谱泄漏也会让某些单元出现非零值。因此,一个检测单元里的观测值可分成两种情况理解。
没有目标时:
有目标时:
很多教材会把这件事写成二元假设检验:
这里的 $x$ 是当前单元的观测值,$n$ 表示背景噪声或杂波,$s$ 表示目标信号。$H_0$ 表示“这里只有背景”,$H_1$ 表示“目标叠加在背景上”。
这个写法看起来正式,含义其实很直白:眼前这个数值,到底只是背景起伏,还是背景上真的叠加了目标?
只找局部最大值不能回答这个问题。比如
第 3 个单元确实比左右两边都高,但它未必是真目标。局部最大只说明它是这一小段里的峰,不说明它高到了足以可信的程度。检测还需要一个判断标准。
阈值检测规则
最基础的判断标准是阈值。设当前单元的幅度为 $x$,阈值为 $T$。若
就报目标;若
就不报目标。写成判决规则为
如果用一个函数表示检测器的输出,可以写成
其中 $\delta(x)=1$ 表示该单元被标为目标,$\delta(x)=0$ 表示不报目标。对一整条距离像或一整张距离-速度图逐格执行这个判决,就会得到一张检测掩码。
这个规则看上去直白,但它背后已经有代价。阈值设低了,容易把噪声当成目标;阈值设高了,容易把弱目标漏掉。固定阈值、CFAR,以及更复杂的统计检测方法,最后都要把一个连续变化的观测值变成“报”或“不报”。差别主要在于阈值怎么来、背景怎么估计、愿意承担多少虚警和漏检。
6.2 检测阈值与固定阈值检测
上一节已经把检测问题压缩成一句话:某个单元的输出值,超过多大才算目标?这个“多大”,就是阈值。
阈值看上去只是一个数,却决定了检测器的取向:是宁可多报也不放过,还是宁可保守也不轻易报警。
固定阈值检测
如果背景比较稳定,先用一个常数作为阈值。假设某段时间内没有目标时,距离单元幅度大多在 0.6 到 1.4 之间波动。此时把阈值设为 $T=2.0$,超过 2.0 就报目标,没超过就不报目标。这就是固定阈值检测。
规则仍然是
其中 $T$ 是预先设定好的常数。背景若长期在 1 左右,1.1、1.2 这类起伏通常不值得报告;某个单元突然到 4 或 5,就更像目标。固定阈值的价值在于给出一把基础标尺,让检测动作先变得可重复。
例如,若 $T=2.0$,某单元输出 $x=4.7$,因为
所以判为有目标。若某单元输出 $x=1.1$,因为
所以判为无目标。这样的判决通常没有太多争议。
麻烦出在边缘区域。若某单元输出 $x=1.9$,按规则
仍然判为无目标。但 1.9 已经比背景高不少,它可能是弱目标,也可能是背景起伏。固定阈值把复杂判断压成了一个数,优点是简单,代价是边缘情况会变得敏感。
阈值高低的后果
阈值降低,弱目标更容易被检出,但噪声也更容易越过阈值。看一组没有目标时的数据:
如果阈值是 $T=2.0$,这组数据不会触发报警。若把阈值降到 $T=1.3$,其中 1.4 和 1.5 都会报警。问题在于,这里假设并没有目标,报警完全由背景起伏造成。
反过来,阈值升高会减少误报,但弱目标更容易被漏掉。假设某个弱目标所在单元的输出是 $x=2.8$。当阈值为 $T=2.0$ 时,
它能够被检出。若把阈值提高到 $T=3.5$,则
它会被判为无目标。
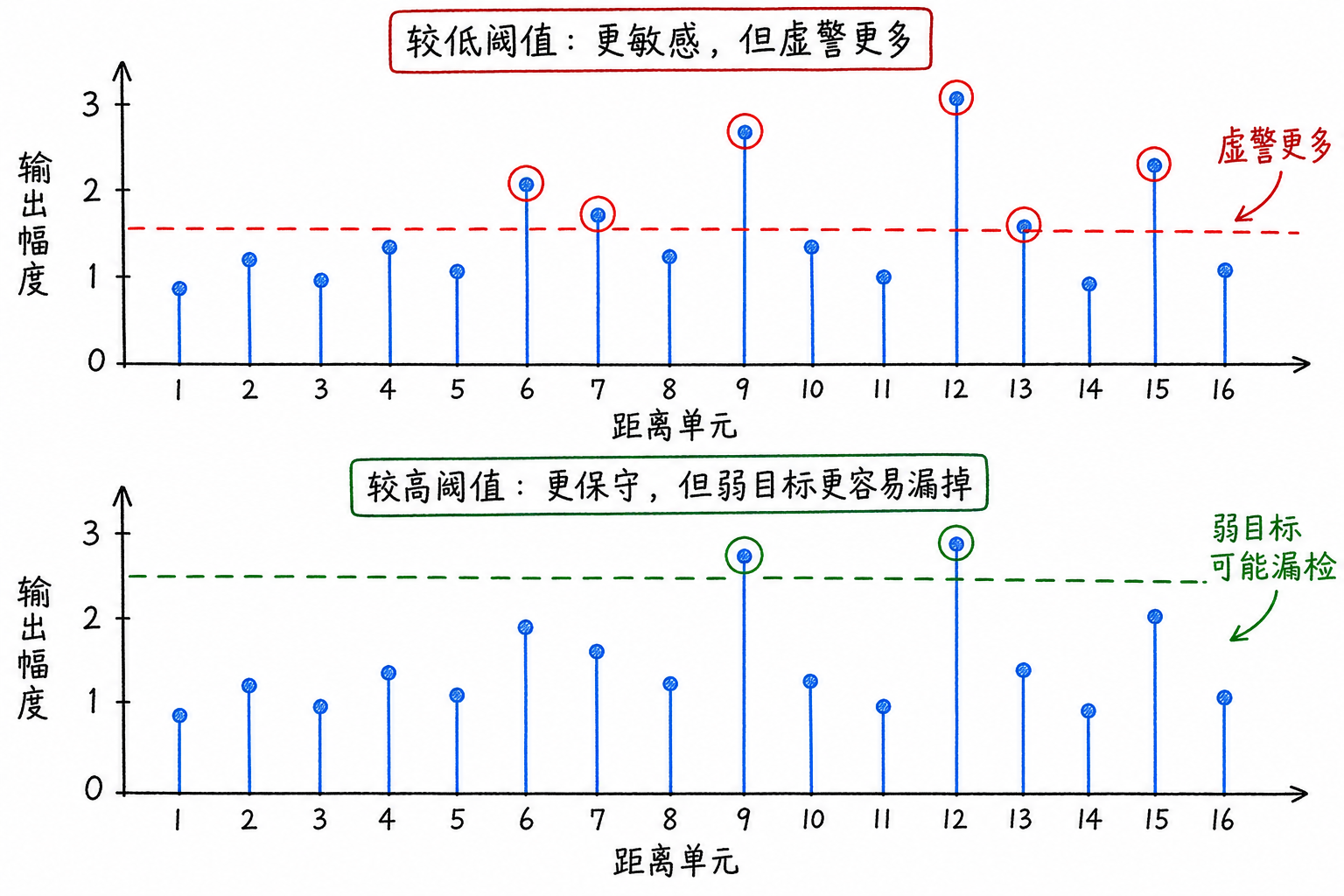
图6.2 展示了同一组数据在不同阈值下的结果。阈值低,报警单元更多,其中一部分可能只是背景;阈值高,报警单元减少,弱目标也可能被挡在阈值之下。检测器从一开始就面对一个取舍:保守一些,还是敏感一些。
背景对固定阈值的限制
固定阈值还有一个前提:背景水平不能差得太远。若整张图的背景都差不多,一个常数阈值可能还能使用。真实雷达图上,背景常随距离、方位、速度单元或环境变化而变化。
例如,同一条距离像中有两个区域。区域 A 背景大致在 1 左右:
若固定阈值 $T=2.0$,中间的 2.6 会被检出。区域 B 的背景抬高到 4 到 6 附近:
同样使用 $T=2.0$,几乎整片区域都会报警。区域 B 并不是到处都有目标,问题出在阈值低于那一带的背景水平。
如果为了适应区域 B,把固定阈值抬到 6.0,区域 A 中一些真实但较弱的目标又可能被漏掉。一个全局常数很难同时适应干净区域和杂波区域。固定阈值适合建立第一层直觉,也适合背景稳定的简化场景;背景明显变化时,就需要让阈值跟着本地背景调整。
6.3 虚警、漏检与检测性能
上一节已经看到,阈值不可能同时取低又取高。阈值降低时,弱目标更容易被检出,噪声也更容易越过阈值;阈值升高时,误报减少,弱目标也更容易被挡住。
工程上不能只凭“感觉差不多”来设计检测器,还需要用明确指标描述检测性能:误报出现得多频繁,漏掉目标的概率有多大。
虚警率、漏检率与检测概率
这两类错误不能混在一起讨论。
在实际上没有目标时,检测器却报出了“有目标”,这叫虚警。在大量无目标测试中,虚警出现的比例称为虚警率,记作 $P_{FA}$。
在实际上有目标时,检测器却没有报出来,这叫漏检,漏检概率常记作 $P_M$。与之对应,在实际上有目标时,检测器成功报出目标的概率称为检测概率,记作 $P_D$。有目标时,要么检出,要么漏检,因此
看一个计数例子。让雷达在无目标条件下工作 100 次,结果有 8 次报警,那么
虚警率为 8%。再让雷达在有目标条件下工作 100 次,成功报出目标 83 次,没有报出 17 次,则
这些指标把“检测效果好不好”拆成了可以比较的量。一个检测器可能虚警少但漏检多,也可能检出率高但虚警多。只说“看起来还行”不够,至少要说明它在哪个虚警水平下达到怎样的检测概率。
阈值权衡与 ROC 曲线
假设背景噪声的幅度大多分布在 0 到 2 之间,弱目标叠加背景后的输出大多分布在 1 到 3 之间。两个范围有重叠:一些较大的噪声样本会到 1.8、1.9,较弱的目标样本也可能只有 1.5、1.7。
只要两类样本有重叠,就不存在一条完美分界线。阈值设在 1.2,很多目标能检出,但不少噪声样本也会越线;阈值设在 2.5,虚警会少,但一些弱目标也会被挡住。
| 阈值 | 检测概率 $P_D$ | 虚警率 $P_{FA}$ |
|---|---|---|
| 1.2 | 0.97 | 0.22 |
| 1.8 | 0.88 | 0.08 |
| 2.5 | 0.65 | 0.01 |
从表中可以看到,阈值取 1.2 时,检测概率高,虚警率也高;阈值取 2.5 时,虚警率低,检测概率也降下来;阈值取 1.8 时处在中间位置。这类表格在工程上很有用,因为它把“灵敏”和“可靠”之间的取舍摆到了同一张表里。
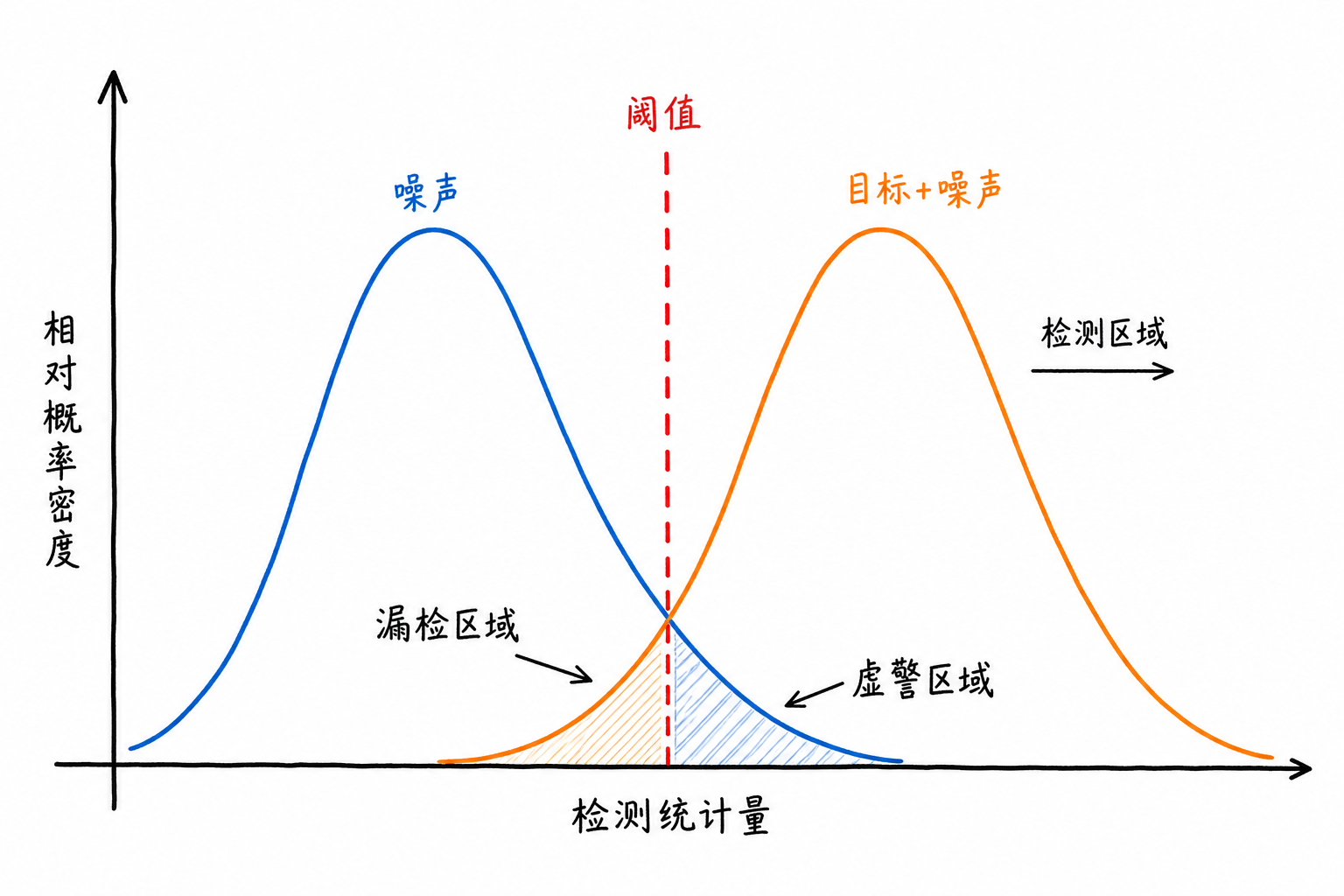
图6.3 用两个分布展示了这个矛盾。蓝色区域代表背景噪声,橙色区域代表目标叠加背景后的输出。阈值往左移,更多目标越过阈值,更多噪声也越过阈值;阈值往右移,噪声越线变少,弱目标也更容易被漏掉。
把不同阈值对应的 $(P_{FA},P_D)$ 点连起来,就得到 ROC 曲线。
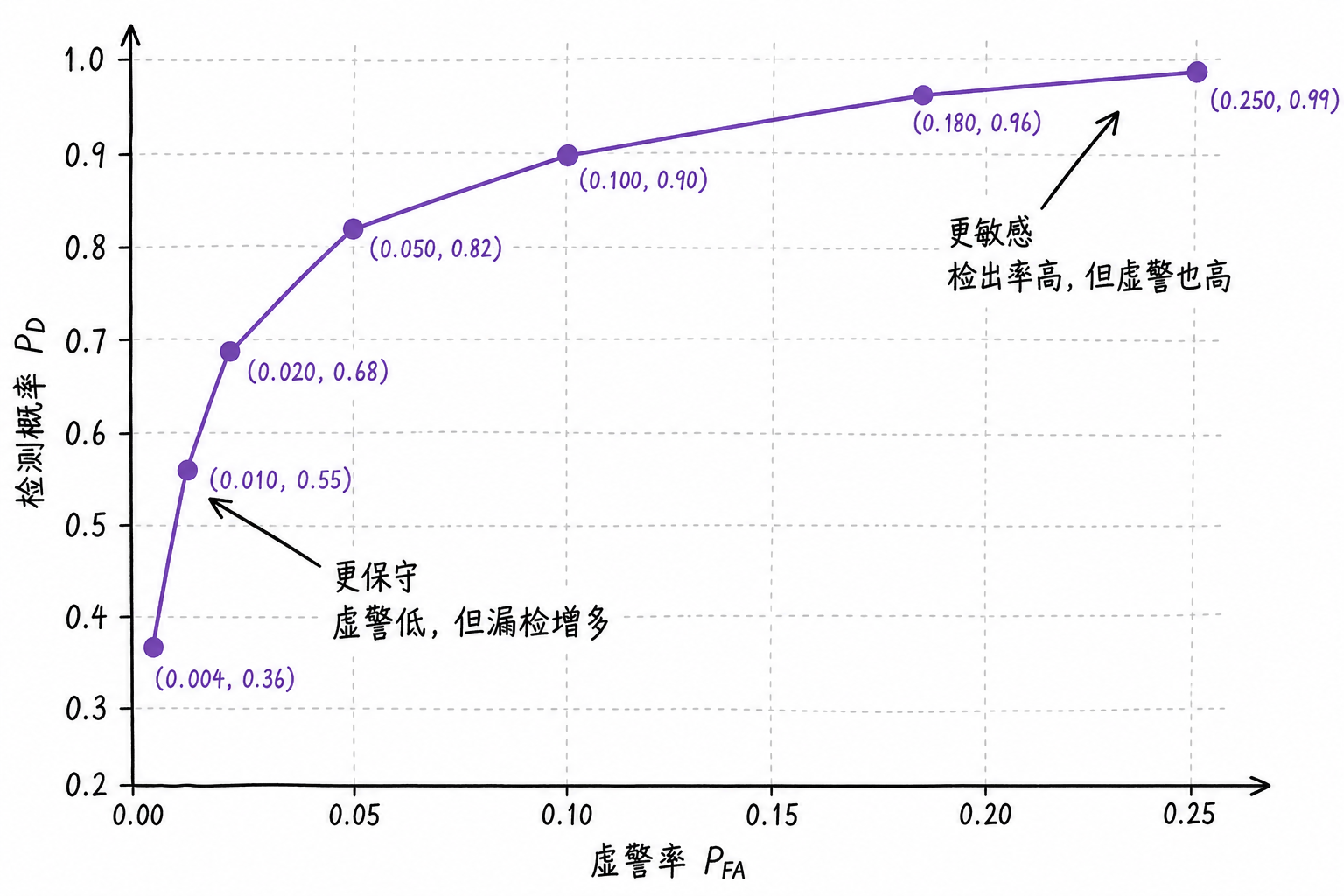
ROC 曲线的横轴是虚警率,纵轴是检测概率。曲线越靠左上,说明在较低虚警率下仍能保持较高检测概率。入门时不需要推导 ROC 的统计来源,先抓住它的读法:同一个检测器在不同阈值下,会沿着曲线移动;想要更高的 $P_D$,通常要接受更高的 $P_{FA}$。
虚警约束与信噪比
实际系统常常先规定一个可以接受的虚警水平。例如,每 1000 个无目标单元平均只允许 1 个虚警,或者每一帧距离-速度图中虚警数量不能多到淹没后端处理。有了这样的要求,再去选择阈值。
这就是“按虚警率设计阈值”的思路。完整的检测理论会进一步讨论 Neyman-Pearson 准则:在给定虚警率约束下尽量提高检测概率。本书只保留这个背景,不展开似然比检验推导。
另一个影响检测难度的量是信噪比(Signal-to-Noise Ratio, 信噪比)。功率形式下可以写成
其中 $P_s$ 是目标信号功率,$P_n$ 是噪声功率。信噪比较高时,目标样本和背景样本更容易分开;信噪比较低时,两类样本重叠更多,同样的阈值更容易同时带来虚警和漏检。
阈值负责做判决,信噪比决定这个判决有多难。若目标本身很弱、背景又强,阈值再怎么调,也不可能把所有错误消掉。检测器能做的是在可接受的虚警水平下尽量提高检出能力。
固定阈值把这个取舍压在一个全局数值上。若整张图背景稳定,这个数还可以工作;若背景在不同区域抬高或降低,同一个阈值就会在某些地方过低,在另一些地方过高。CFAR 正是为这种情况准备的。
6.4 恒虚警率检测(CFAR)
前面几节讨论阈值时,一直有一个隐藏前提:背景大致稳定。只有在这个前提下,固定阈值才像一把通用尺子,放到哪里都差不多能用。
真实环境往往不是这样。近距离可能杂波更强,远距离噪声底可能更低,某些方位上有地物、海浪或雨区,距离-速度图不同区域的起伏水平也可能完全不同。这时固定阈值容易出现这样的结果:在安静区域偏高,在嘈杂区域又偏低。
从固定阈值到局部阈值
CFAR 是 Constant False Alarm Rate 的缩写,通常译为恒虚警率。它的出发点是把阈值从写死的常数,改成根据周围背景自动调整的量。
仍然看前面的两个区域。区域 A 背景在 1 左右,中间 2.6 确实高出不少;区域 B 背景在 5 左右,中间 5.8 并不突出。如果用固定阈值 $T=2.0$,区域 B 会大量报警。若每个位置都先看附近背景,再把阈值设成背景的若干倍,区域 A 和区域 B 就会得到不同阈值。
这个动作可以概括为三步:先估计当前单元附近的背景水平,再按目标虚警率留出余量,最后把当前单元与这个局部阈值比较。
在一维距离像上,它表现为滑动窗口;在二维距离-速度图上,它表现为围绕某个格子的邻域窗口。下面用一维窗口说明,因为它最容易看清 CUT、保护单元和参考单元的作用。
CUT、保护单元和参考单元
要判断的当前单元称为被检测单元,常写成 CUT(Cell Under Test)。假设一串数据为
中间的 3.2 是 CUT。若用周围 6 个单元估计背景,平均值为
如果阈值取背景估计的 3 倍,则
CUT 为 3.2,满足
于是判为目标。这个例子已经包含了 CFAR 的主要动作:本地估计背景,本地生成阈值,本地做判决。
真实处理中,紧挨着 CUT 的单元不能用于背景估计。目标响应通常不只落在一个格子上,主瓣边缘和旁瓣可能影响附近单元。若这些单元参与平均,背景估计会被目标能量抬高,阈值随之变高,弱目标反而更容易被漏掉。
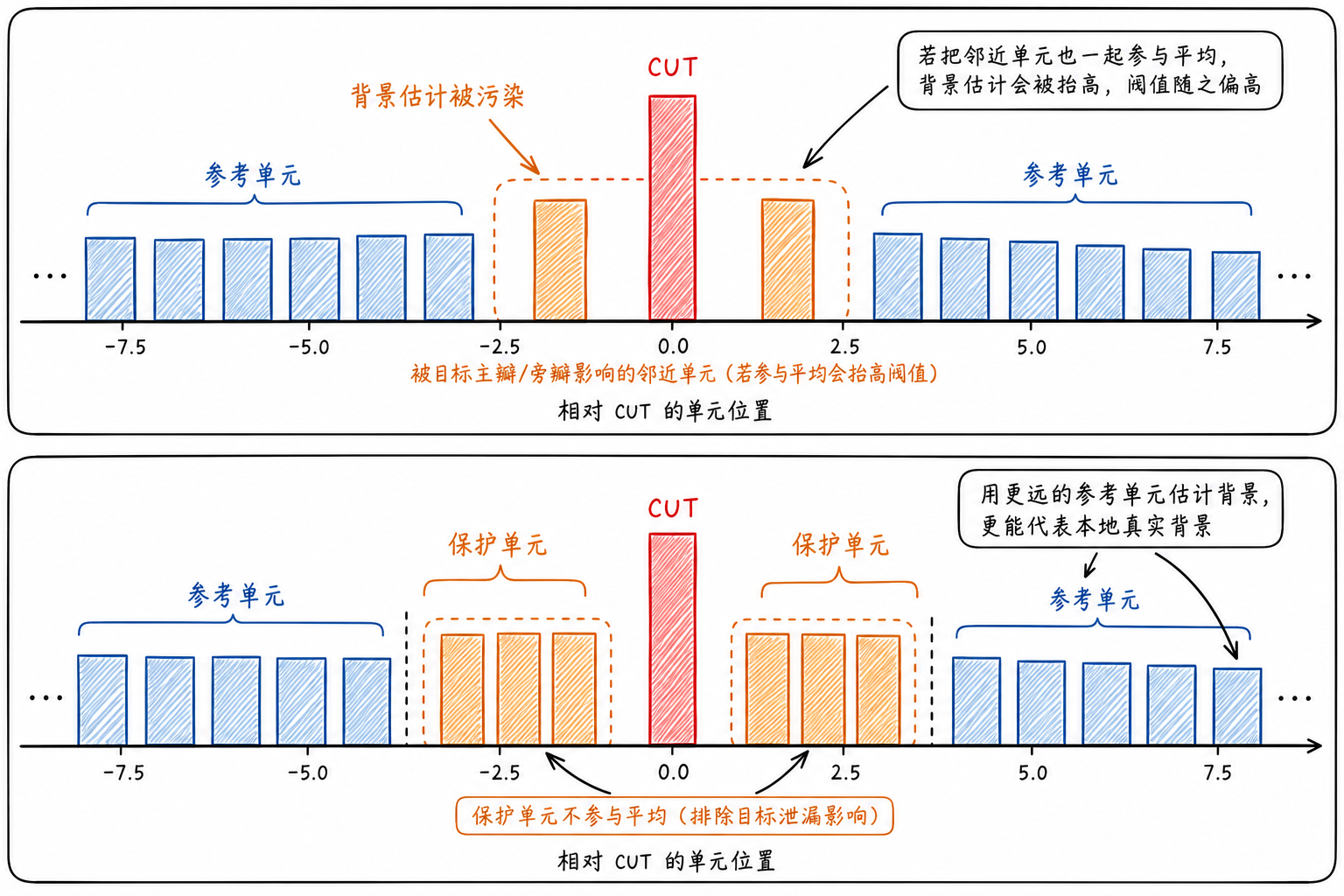
因此,CUT 两侧会留出保护单元(Guard Cells)。保护单元不参与背景估计,只负责隔开 CUT 和参考区域。更远处的一批单元称为参考单元(Reference Cells),用来估计局部背景。
一维 CA-CFAR 的窗口可以写成
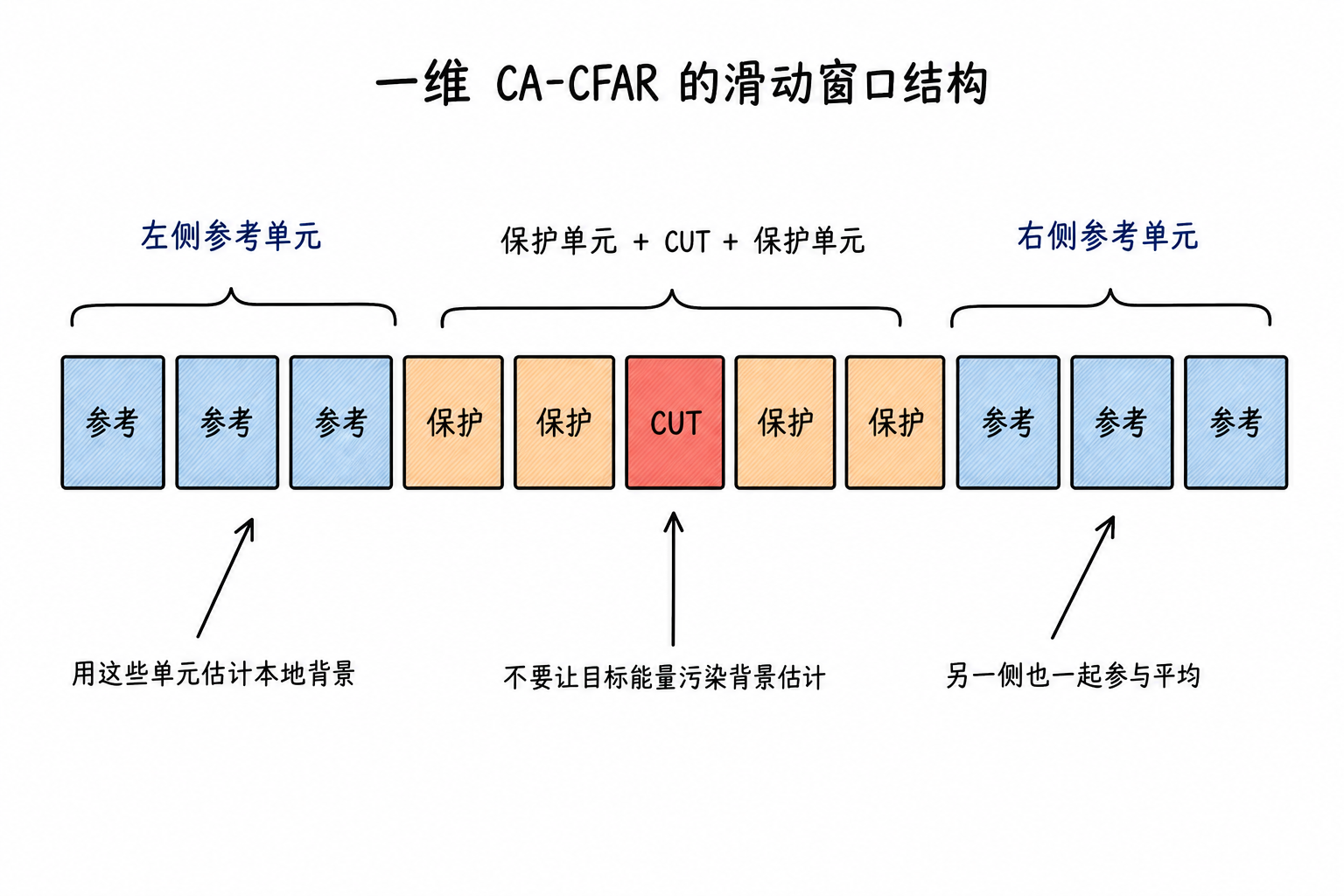
保护单元回答的是“哪些地方可能已经被目标影响,不适合拿来估背景”;参考单元回答的是“这一带背景大概有多高”。两个角色分清楚后,CFAR 的窗口结构就不难理解。
CA-CFAR 的计算与局限
最基础的一类 CFAR 是 CA-CFAR,CA 表示 Cell Averaging,即单元平均。它用参考单元的平均值估计背景功率或幅度,再乘以阈值系数,形成局部阈值。
功率形式下可以写成
其中 $\hat P_n$ 是参考单元估计出的局部背景,$\alpha$ 是阈值系数。然后比较
$\alpha$ 不能省。若阈值只等于背景平均值,背景中稍高一点的起伏就很容易越线,虚警会很多。$\alpha$ 提供的是安全余量:$\alpha$ 越大,阈值越高,虚警越少,弱目标也越难检出。严格的 $\alpha$ 与 $P_{FA}$ 关系需要假设背景分布,本书不展开推导。
看一个简化计算。CUT 的功率为 12,两侧参考单元功率为
参考单元平均值为
若 $\alpha=2$,则
因为
所以 CUT 被判为目标。
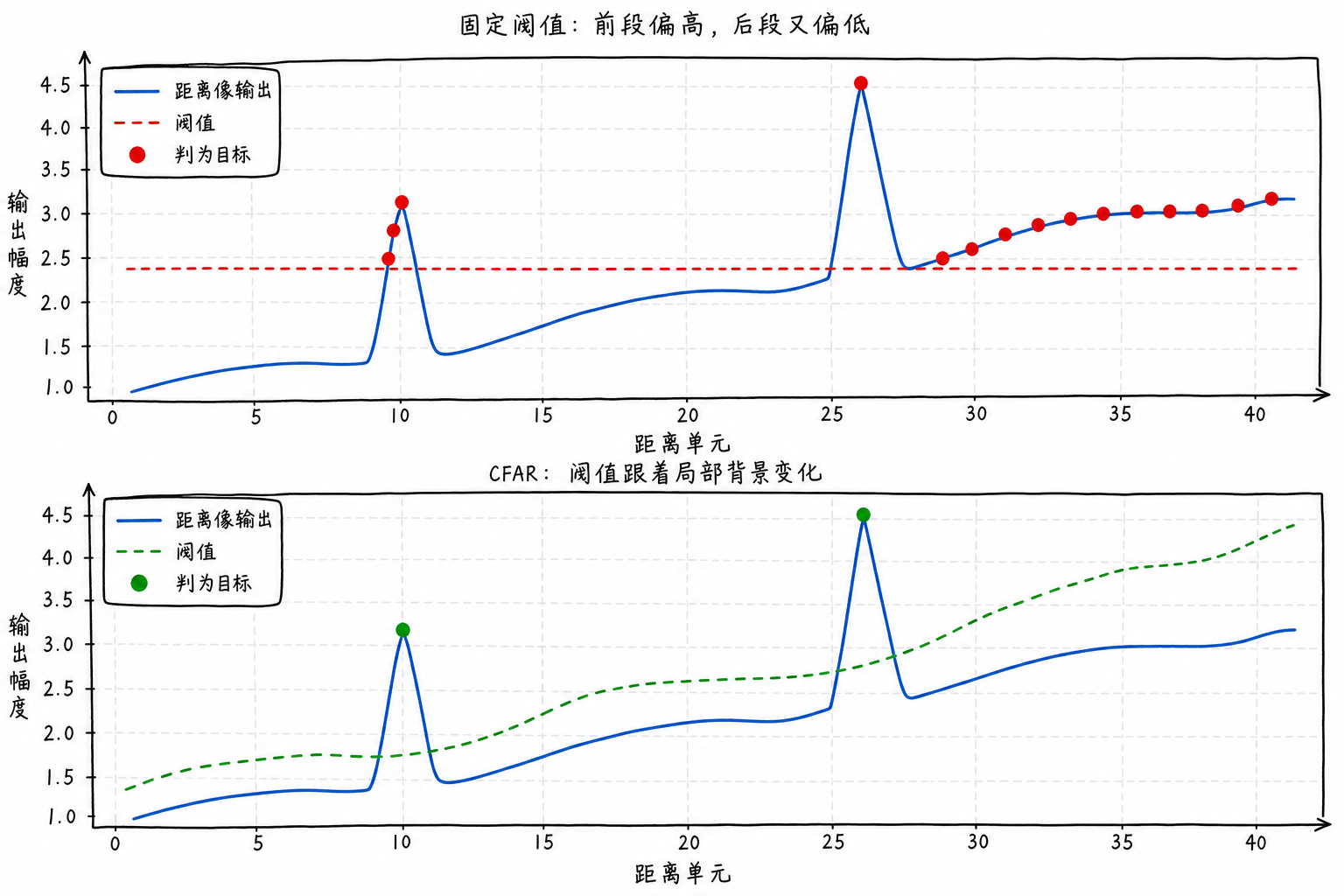
图6.7 把固定阈值和 CFAR 放在同一条背景不均匀的距离像上比较。固定阈值是一条水平线,背景抬高后容易产生连续误报;CFAR 阈值跟随局部背景变化,在不同区域给出不同门槛。
CA-CFAR 也有局限。它默认参考单元能代表本地背景。若参考单元里混进另一个强目标,平均值会被抬高,当前弱目标可能被漏掉;若窗口跨过杂波边缘,一侧背景高、一侧背景低,简单平均也不一定合适;目标密集时,参考单元很难保持“纯背景”。
这些局限不会推翻 CFAR 的框架。CUT、保护单元和参考单元仍然存在,变化主要发生在“怎样用参考单元估计背景”这一步。
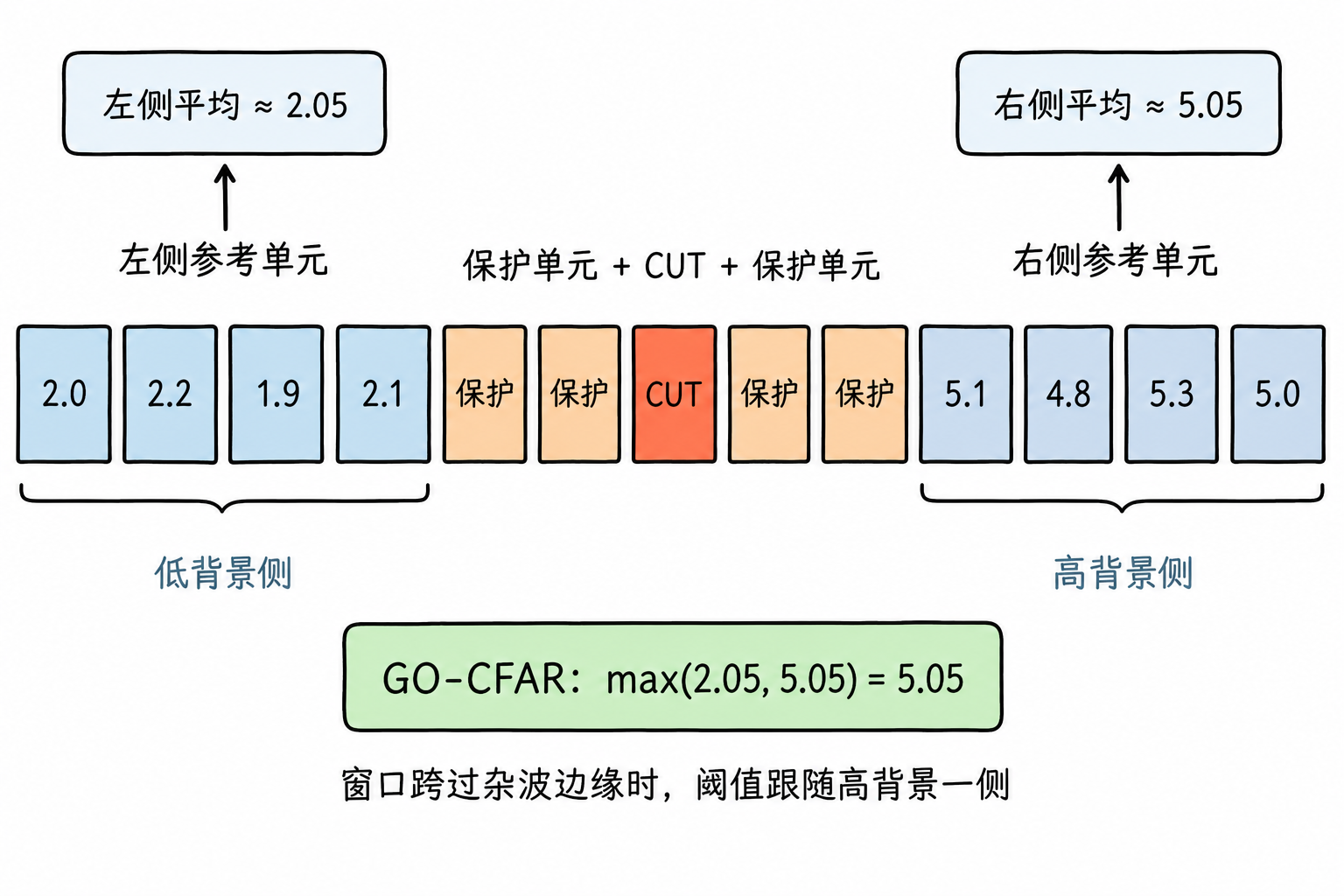
一种常见变体是 GO-CFAR,GO 表示 Greatest Of。它把 CUT 左右两侧的参考单元分开计算,例如左侧求一个平均值,右侧再求一个平均值,最后取两者中较大的那个作为背景估计。这样做偏保守:如果窗口正好跨过杂波边缘,高背景一侧会把阈值抬起来,能够减少杂波边缘附近的误报。代价是阈值可能偏高,靠近高杂波区域的弱目标更容易漏掉。
另一种常见变体是 OS-CFAR,OS 表示 Ordered Statistic,即有序统计。它先把参考单元的数值从小到大排序,再选其中某个排名位置的值作为背景估计。这样做的好处是,一两个特别强的参考单元不容易像平均值那样把阈值整体拉高,所以 OS-CFAR 常用于目标较密集、参考窗口容易被其他目标污染的情况。它的代价是多了一个“排名位置”参数;位置选得偏高,检测会更保守,选得偏低,又可能带来更多虚警。
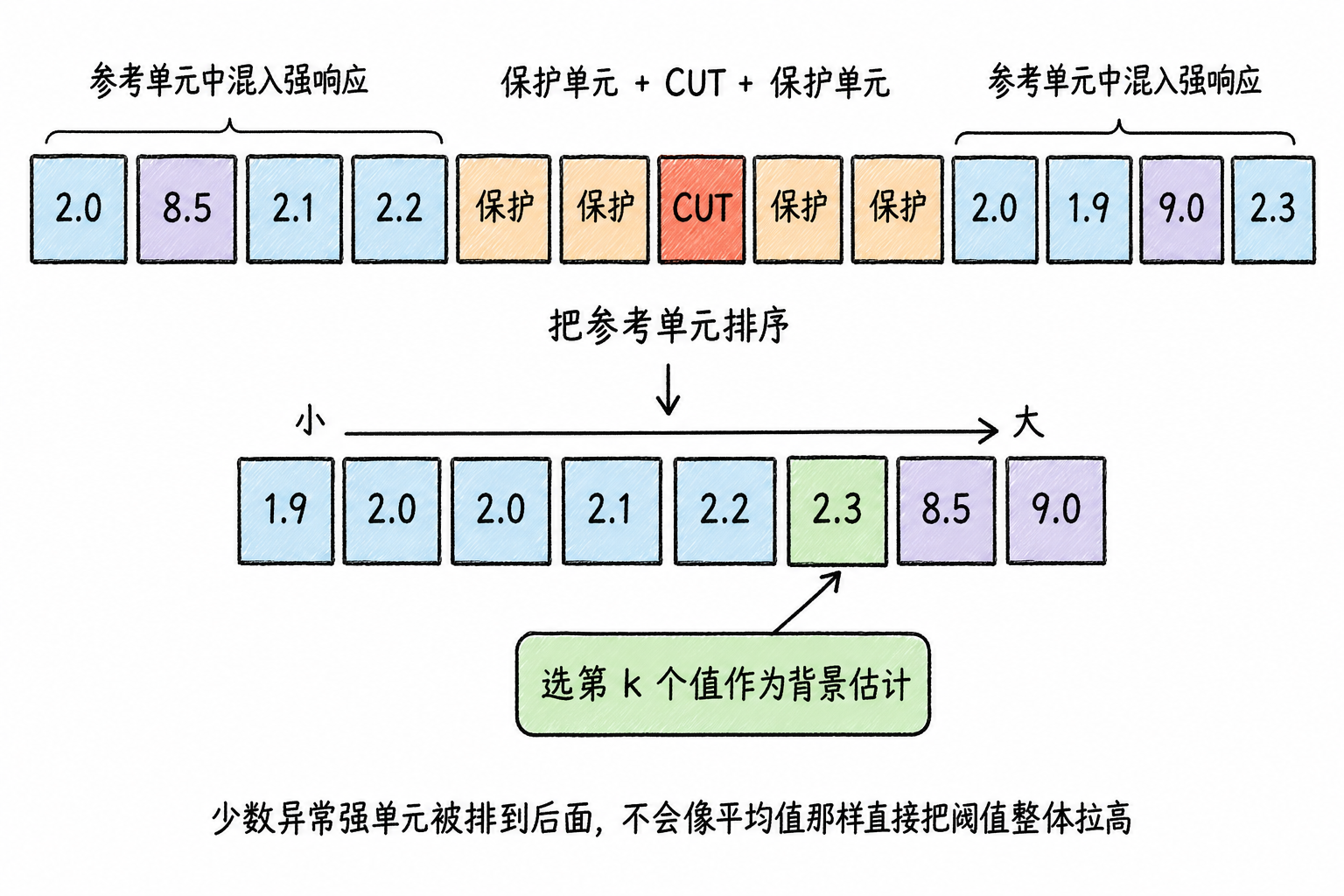
所以,CA-CFAR 适合背景相对均匀的入门场景;GO-CFAR 更强调在杂波边缘压住误报;OS-CFAR 更强调在多目标或异常点污染下保持背景估计稳定。它们解决的问题不同,但仍然都在做同一件事:先估计 CUT 附近的背景,再把当前单元和局部阈值比较。
6.5 点迹凝聚:从检测单元到目标点迹
固定阈值或 CFAR 逐格做判决后,系统得到的是检测掩码:哪些距离单元、速度单元通过了检测门限。但这张二值图里的每一个 1,并不一定都代表一个独立目标。
如果逐格上报,同一辆车、同一架飞机或同一片雨区,可能会被拆成好几个目标。这里先把点迹理解为一条候选目标记录;点迹凝聚处理的就是检测之后的整理工作:把相邻的报警合并或筛选,形成后续处理更容易使用的目标点迹。
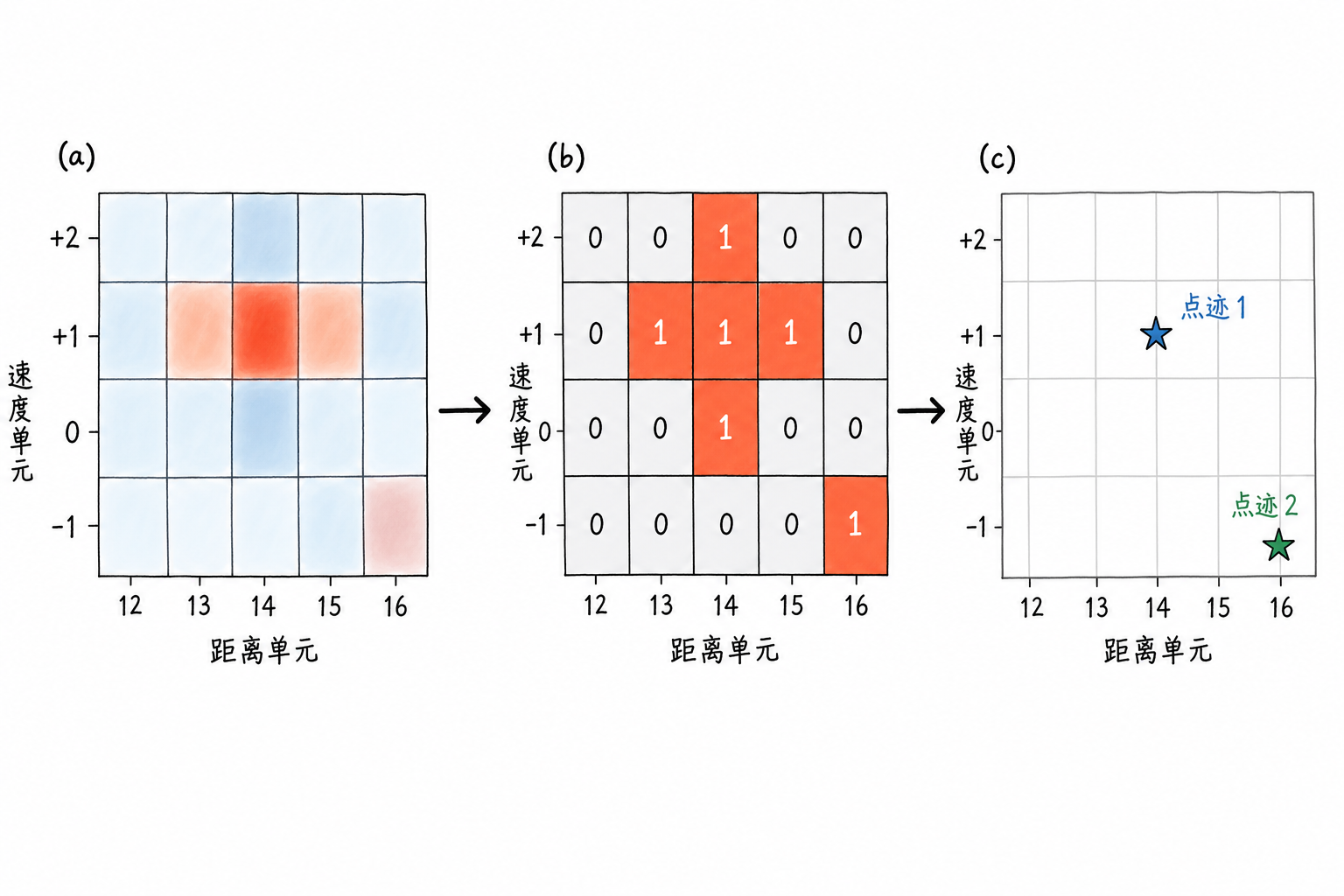
图6.10 把这三层关系放在一起:距离-速度图保存连续变化的响应强度;检测掩码只保留过门限的位置;点迹凝聚再把相邻报警整理成少量候选目标记录。
为什么一个目标会亮起一片单元
理想点目标可以想成只落在一个距离-速度单元里;实际距离-速度图往往更宽。脉冲压缩后的主瓣有宽度,FFT 后的谱峰也有宽度,窗函数、旁瓣、目标尺寸和网格位置都会让能量扩散到附近单元。只要附近单元也超过阈值,它们就会在检测掩码中一起变成 1。
例如某个局部距离-速度区域的检测结果为:
| 速度单元 / 距离单元 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|
| +2 | 0 | 0 | 1 | 0 | 0 |
| +1 | 0 | 1 | 1 | 1 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 |
这 5 个检测单元很可能来自同一个目标的响应,而不是 5 个目标排成十字形。若不做凝聚,目标列表会被重复报警填满,后面的显示、航迹处理和人工判读都会被干扰。
因此,检测后的第一步是先看相邻报警是否属于同一片候选区域,再决定怎样上报。
连通区域、局部峰值与点迹参数
一种直观做法是先找连通区域。在一维距离像里,相邻距离单元连续为 1,可以看成一组;在二维距离-速度图里,距离方向或速度方向相邻的检测单元,也可以归为同一组。工程实现时可以采用 4 邻域或 8 邻域,入门阶段只要抓住一点:彼此挨在一起的报警,先按一片候选目标区域处理。
找到一片区域后,还要选出代表位置。简单规则是取原始幅度或功率最大的单元,作为这片区域的峰值点。以上面的十字形区域为例,若最强响应出现在距离单元 14、速度单元 +1,就可以把点迹位置记为这个格子,再附带幅度、信噪比、区域大小等信息。
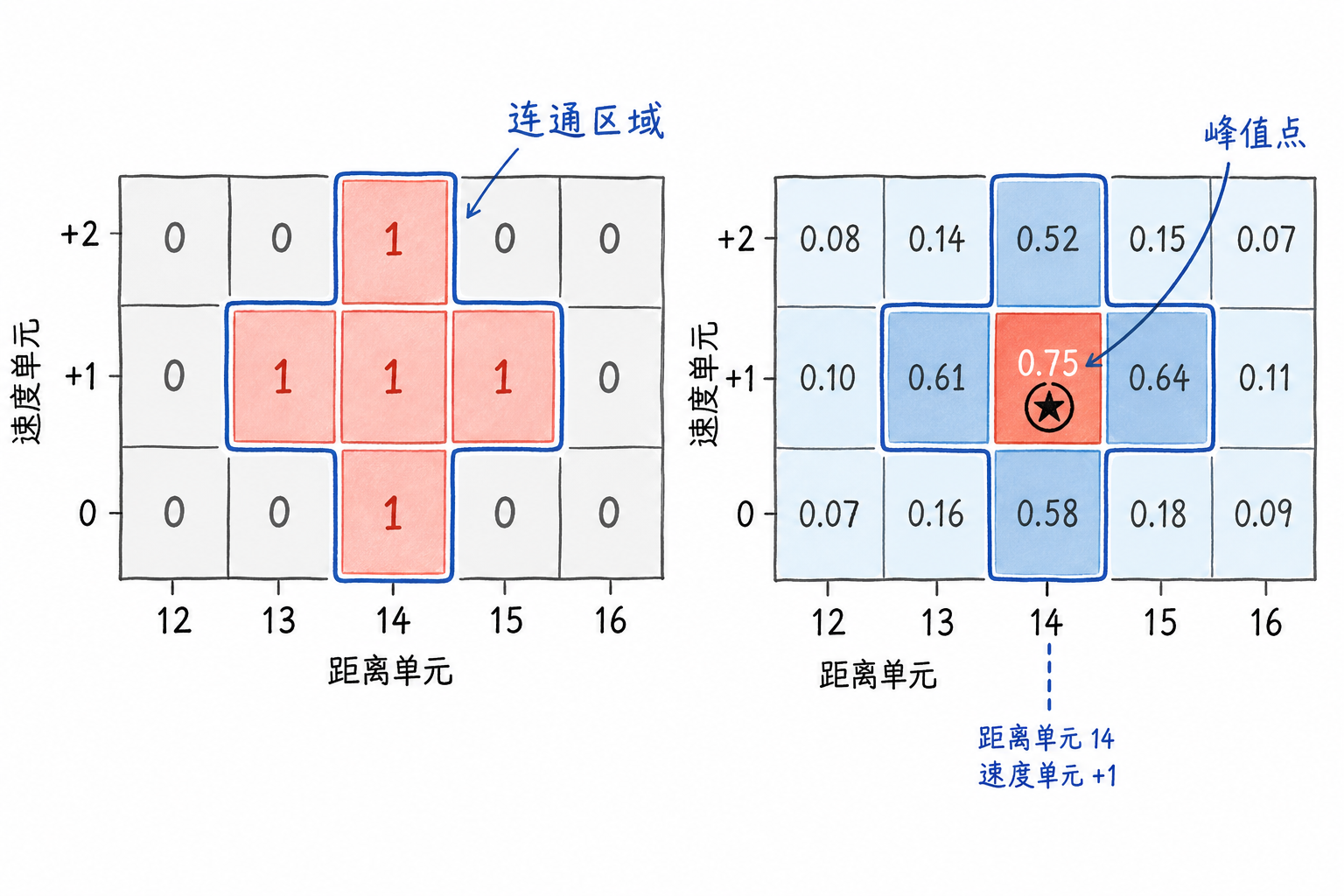
图6.11 左侧表示检测掩码里的相邻报警,右侧把原始响应强度放回同一片区域中。区域内最强的格子被选为峰值点,它的位置就成为这条点迹的代表位置。
有些系统不先显式找连通区域,而是做局部峰值筛选:一个检测单元只有在距离方向、速度方向上都比邻近单元更像峰值时,才保留下来。这个思路和连通区域法并不矛盾。二者都在避免同一个目标附近的多个报警被重复上报。
雷达里常把这类检测报告称为点迹。这个名字可以拆开理解:凝聚以后,它在当前这一帧数据里表现为一个代表位置,所以是一个“点”;这个点来自一次观测,是目标在这一帧里留下的检测记录,所以称为“迹”。点迹强调的是单帧观测留下的候选目标位置。
一条点迹通常会记录它所在的距离单元、速度单元、换算后的物理距离和径向速度,也会记录幅度或信噪比,用来表示这条点迹有多强。实际系统还可能记录目标区域的宽度、所在波束、时间戳等字段。
点迹凝聚也会带来取舍。凝聚太强,距离或速度很接近的两个目标可能被合成一个点迹;凝聚太弱,一个目标又可能被拆成多个点迹。因此,凝聚规则要和距离分辨率、速度分辨率、CFAR 窗口以及目标场景一起考虑。
点迹只是单帧检测结果,还不是航迹。航迹需要在多帧之间把点迹关联起来,再估计目标运动状态。在本章的处理链条中,距离-速度图给出响应强度,检测得到检测掩码,点迹凝聚把相邻报警整理成目标点迹。
6.6 小练习
练习 1:固定阈值判决
某距离单元输出幅度为 $x=2.7$,固定阈值取 $T=2.0$。该单元应判为有目标还是无目标?
解析:比较当前单元和阈值。因为
所以判为有目标。这个练习对应检测器的第一步动作:把连续数值变成离散判决。
练习 2:阈值升高后的后果
某弱目标所在单元输出为 $x=2.4$。当阈值从 $T=2.0$ 提高到 $T=2.8$ 时,检测结果如何变化?
解析:当 $T=2.0$ 时,
该单元被判为有目标。阈值提高到 $T=2.8$ 后,
结果变成判为无目标。阈值升高会减少一部分虚警,也会让弱目标更容易漏掉。
练习 3:虚警率、检测概率和漏检率
某检测器在 200 次无目标测试中误报 6 次;在 150 次有目标测试中成功检测到 129 次。求 $P_{FA}$、$P_D$ 和 $P_M$。
解析:虚警率为
检测概率为
漏检率为
因此,虚警率为 3%,检测概率为 86%,漏检率为 14%。
练习 4:背景变化下的固定阈值
在同一幅距离像中,区域 A 的背景大致在 1 左右波动,区域 B 的背景大致在 5 左右波动。若统一使用固定阈值 $T=3$,两个区域会出现什么差异?
解析:在区域 A 中,阈值 3 高于背景不少,虚警不会太多,只有明显高出的峰值才会触发。在区域 B 中,背景本来就在 5 左右,阈值 3 低于大量背景起伏,会触发许多误报。固定阈值默认整个场景背景差不多,背景不均匀时就会失衡。
练习 5:一个简化的 CA-CFAR 计算
某一维距离像中,待检测单元 CUT 的功率为 12。两侧参考单元功率为
保护单元已经跳过,不参与计算。若阈值系数取 $\alpha=2$,该单元是否判为目标?
解析:先计算参考单元平均值:
局部阈值为
最后比较 CUT 与阈值:
所以该单元判为有目标。
练习 6:保护单元的作用
如果把紧挨着 CUT 的单元也放进参考单元平均里,可能出现什么问题?
解析:若 CUT 附近确实有目标,目标主瓣边缘或旁瓣能量可能泄漏到相邻单元。把这些单元拿去估计背景,会抬高背景平均值,阈值也会随之升高。原本应该检出的弱目标,可能因此落到阈值以下。保护单元用来减少这种目标能量对背景估计的污染。
练习 7:CA-CFAR 的失效场景
设想两个强目标距离很近,或者某一侧参考单元落在很强的杂波区内。简单 CA-CFAR 可能遇到什么困难?
解析:CA-CFAR 依赖参考单元估计本地背景。两个强目标靠得很近时,参考单元里可能混入另一个目标,平均值被抬高;窗口跨过杂波边缘时,一侧参考单元不能代表另一侧背景。两种情况都会让阈值偏离当前 CUT 附近的真实背景,可能造成漏检或虚警。这也是工程上发展 GO-CFAR、OS-CFAR 等变体的原因。
练习 8:从距离-速度图到检测掩码
假设第5章已经得到一张距离-速度图。请描述如何用固定阈值或简化 CA-CFAR 得到检测掩码,并说明掩码中的 1 表示什么。
解析:固定阈值做法是逐格比较距离-速度图中的幅度或功率:超过阈值的位置置为 1,否则置为 0。简化 CA-CFAR 做法是逐格选取 CUT,在 CUT 周围留出保护单元,再用参考单元估计局部背景,生成局部阈值,最后比较 CUT 与阈值。
检测掩码中的 1 表示该格子通过了检测门限,可以作为候选目标继续处理。它还不是完整目标列表;还需要把格子索引换成距离、速度坐标,并通过点迹凝聚处理相邻格子的合并、峰值选择等问题。
练习 9:从检测掩码到点迹
某个局部检测掩码如下:
| 行号 / 列号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 1 | 0 | 0 |
| 3 | 0 | 1 | 1 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 |
若按相邻单元连通来做点迹凝聚,这个掩码大致会形成几条点迹?如果左上方那片区域中第 2 行第 3 列的原始幅度最大,可以怎样选它的代表位置?
解析:左上方的 4 个 1 彼此相邻,应先看成一个候选区域;右下角的 1 与它们分开,应看成另一片区域。因此,这个局部掩码大致形成 2 条点迹。
左上方区域若第 2 行第 3 列幅度最大,可以把这个格子作为该区域的峰值点,点迹位置就取它对应的距离单元和速度单元。若系统还保存原始幅度、信噪比或区域大小,这些量也可以一起写入点迹记录。这个练习对应点迹凝聚的基本动作:先把相邻报警归成候选区域,再为每片区域选一个代表点。